VITS是在TTS领域上里程碑式的模型,为后来的工作产生了不小的影响,包括最近大火的 so-vits-svc 模型也是基于此模型。
Text-To-Speech
首先简单介绍一下 TTS 任务的一般做法,主要由以下三个部分组成:文本预处理、声学模型、声码器。
- 文本预处理:将自然语言文本输入转换为语言特征,这里的特征一般为音素,即发音的最小单元,类似中文的拼音与英文的音标。
- 声学模型:是一个独立的网络,用来将语言特征转换为声学特征,比较常用的声学特征是梅尔倒谱。
- 声码器:也是独立的网络,用来将声学特征转换为声音波形。这里需要用独立的网络来生成,主要是因为之前步骤中生成的特征可能会存在一些电音或是韵律不正常之类的人工痕迹,这部分可以使得生成语音变得更加自然。
前两个部分一般被称为 TTS 前端,声码器被称为后端,所以传统的 TTS 其实是个 two-stage 的结构。
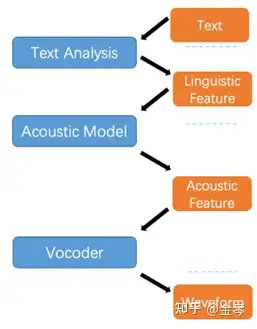
但是使用 two-stage 的结构,一个问题在于两个网络需要独立训练独立推断,所以效率较低;另一个问题在于其之间存在gap,在质量上肯定比不上 end2end 的框架。
VITS
VITS 的诞生就解决了以上问题,它是一个 end2end 的框架,达到了更高的生成效率以及更好的生成效果。同时,VITS 还实现了 one-to-many 的效果,也就是说,对于同样一段文本输入,每次可以有略微不同的韵律和声调,更加符合人类真实的说话。
METHOD
变分推断
VITS 的主体其实是一个变分自编码器(VAE),优化目标即最大化该 VAE 的变分下界(ELBO):
logpθ(x∣c)≥Eqϕ(z∣x)[logpθ(x∣z)−logpθ(z∣c)qϕ(z∣x)]
公式里表示输入条件,可以暂时理解为 ctext ,即为输入的文本特征,z 表示隐变量,x 就是网络输出,可以暂时理解为输出音频, qϕ(z∣x) 即为近似的后验分布。
网络的训练目标是最小化 −ELBO ,这部分可以被看作一个 reconstruction loss −logpθ(x∣z) 和一个 KL 散度 logqϕ(z∣x)−logpθ(z∣c) 的和。
RECONSTRUCTION LOSS
在计算 reconstruction loss 的时候,作者这里使用了梅尔倒谱作为音频波形的表征,然后对其计算 L1 loss。用梅尔频谱主要是因为它比较符合人耳听觉系统,能够提高感知上的质量,同时梅尔频谱不需要额外的网络,只需要经过简单的线性变换。
Lrecon=∥xmel−x^mel∥1
需要注意的是,这里是 VITS 唯一一次用到梅尔倒谱,也就是说,在推断的时候是不需要用梅尔倒谱的。
KL 散度
先前我们把先验概率中的 c 简单当作文本特征,其实不然,这部分应该是 [ctext,A] ,前者是文本的音素表示,即文本特征;后者是一个对齐矩阵,用来表示音素与隐变量之间的对齐。这个 ∣ctext∣×∣z∣ 大小的对齐矩阵是硬单调的,换句话说:每个隐变量只能对齐到一个音素上,同时音素和隐变量之间的对齐具有单调性。先大概有个印象,后面会展开介绍。
同时,我们先前简单当作输出音频的 x ,其实是音频的线性谱,毕竟音频波形不好直接拿来用。这里之所以用线性谱,不适用梅尔谱,主要还是因为线性谱具有更高分辨率的信息。
综合以上两个细节, KL 散度实际上应该写为:
Lkl=logqϕ(z∣xlin)−logpθ(z∣ctext,A)
然后这里作者发现,增加先验分布的复杂度是有利于提高最终生成结果的质量的,所以作者还引入了一个 normalizing-flow 来增加先验分布的复杂度,由于这个东西是可逆的,所以不会影响网络的其他部分。此时,KL 散度的先验分布项可以表示为:
pθ(z∣c)=N(fθ(z);μθ(c),σθ(c))∣det∂z∂fθ(z)∣,c=[ctext,A]
对齐矩阵
MONOTONIC ALIGNMENT SEARCH
为了得到对齐矩阵 A ,作者这里使用了单调对齐搜索(MAS)算法,这个算法的原始形式在 Glow-TTS 中被提出,其实是搜索一个对齐矩阵,以最大化 normalizing flow 分布的似然,即:
A=argA^max logp(x∣ctext,A^)=argA^max logN(f(x);μ(ctext,A^),σ(ctext,A^))
但是本文的优化目标是一个 ELBO ,需要对公式进行化简:
A=argA^max logpθ(xmel∣z)−logpθ(z∣ctext,A^)qϕ(z∣xlin)=argA^max pθ(z∣ctext,A^)
由于公式第一行第一项与第二项的分子都与 A^ 无关,所以可以直接忽略,最后得出的形式如第二行所示,实际上是与 MAS 算法的原始形式相同,所以可以直接不经过改变直接拿来用。
由于矩阵单调以及 non-skipping 的特点,即音素和隐变量需要一一对齐,该算法的计算通过动态规划来实现,将矩阵中各个概率值计算出来,然后搜索最短路径。
DURACTION PREDICTION
对齐矩阵需要通过 pθ(z∣ctext,A^) 来优化,在训练时, z 可以通过后验编码器得到,但是在推断的时候, z 无法获得,因此,需要在训练时直接训练一个时长预测器,以在推断时取代 A ,该预测器直接通过输入的 ctext 预测出其发音时长 d 。在先前的 Glow-TTS 中,也有一个确定的时长预测器,即针对给定的输入,只有确定的时长输出。由于本文要提出更符合真实人类说话的 one-to-many 效果,这里引入的是一个随机的时长预测器,旨在给出一个 d 的分布,在从其中采样。
这里使用的还是一个 flow-based 的结构,然后去优化 logpθ(d∣ctext) 的下界。由于 flow 是基于最大似然估计的,其采样出来的值会是连续的数字,而每个音素的发音时长 d 是离散的整数,所以在推断时,对于预测器的输出结果,还要额外经过一个取整。
需要特别注意的是,由于这个模块相对于整个框架的其他模块来说较为独立,所以需要对参数进行一个 stop gradient 的操作,防止影响其他模块的训练。
对抗训练
在对抗 loss 上,本文除了使用了一组较为传统的 least-squares loss 以外,还添加了一个 feature-matching loss 用来训练生成器,这个 feature-matching loss 可以被看作在判别器上逐层的 reconstruction loss 。
Ladv(D)Ladv(G)Lfm(G)=E(y,z)[(D(y)−1)2+(D(G(z)))2],=Ez[(D(G(z))−1)2],=E(y,z)[Nl∑TNl1∥Dl(y)−Dl(G(z))∥1]
Final Loss
Lvae=Lrecon+Lkl+Ldur+Ladv(G)+Lfm(G)
这部分没什么好说了,就是前面几部分的综合。
Pipeline
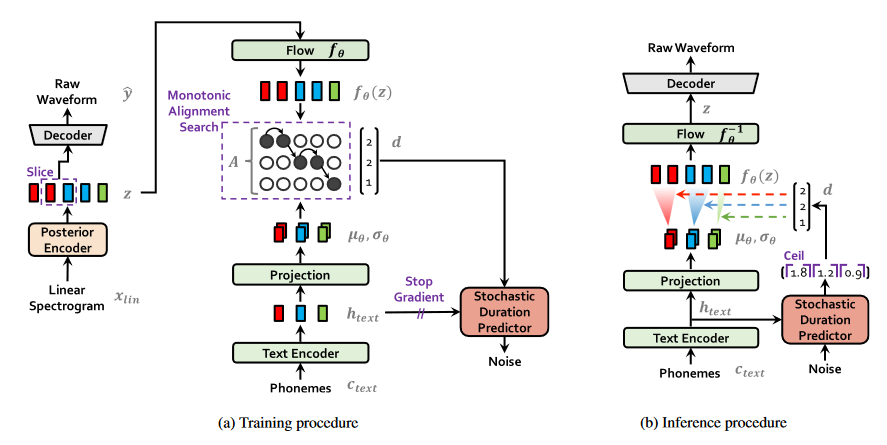
最后看一下 pipeline ,大部分内容前面都已经讲过了,这里再提一些细节:
- 在训练时其实不是把整个 z 丢进 decoder 的,而是将其分窗,这样训练起来更加高效。
- 先验 encoder 实际上包含了一个 transformer encoder 的结构,将 ctext 编码为 htext ,然后再通过 normalizing flow 映射到高维。