这篇文章的工作是在 First Order Motion Model 上的修改。
RELATED WORK
FOMM存在一些问题:
- 比如说两帧之间的keypoints并不能精确地建立好联系,容易出现映射错误,导致运动错误的情况;
- kp只能代表位置和运动方向,不能表征周围域的形状,比如旋转、缩放之类的特征;
- 没有考虑到背景的运动,比如一点微小的相机运动或者背景内容的变化都需要单独的kp进行建模,这样一来首先是需要额外的网络来训练背景的kp,其次是可能导致过拟合,最后导致背景的内容被附近的kp带着运动。
METHOD
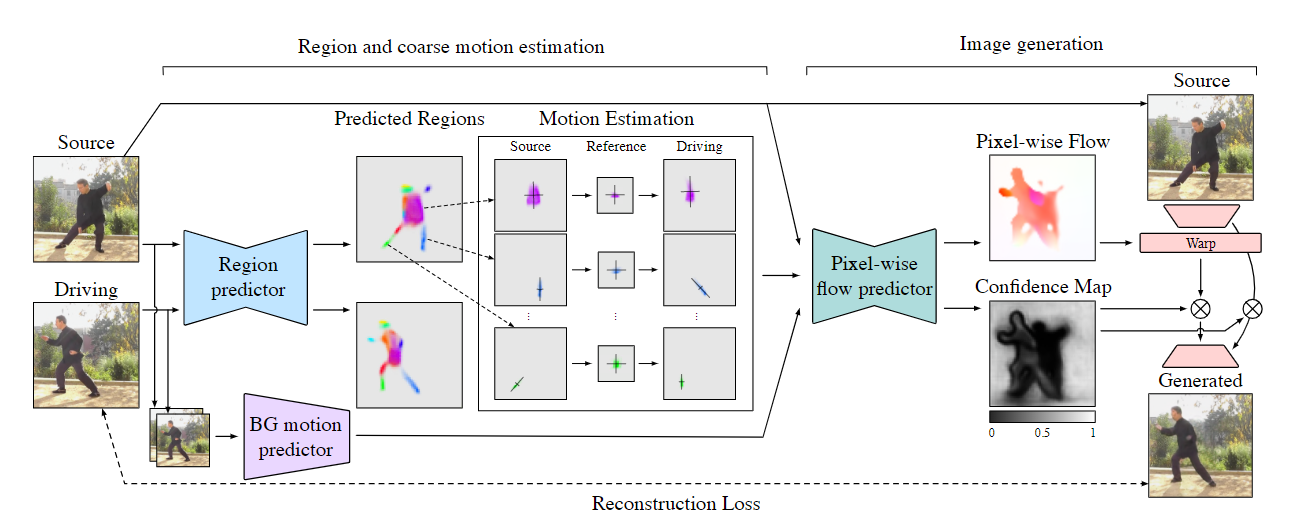
PCA-based运动估计
作者提出,在FOMM中直接对仿射变换参数直接进行回归,需要较大的网络容量,而且建模出来的效果较差。所以在本文中提出了使用region进行预测。
这个region是指 中的 ,也就是对于每一个pk的一张张heatmap。由于平移变换还是需要从kp得出,所以平移还是用原本的方法进行预测,但是旋转和缩放使用 的PCA进行预测。作者这里是用了SVD(奇异值分解)进行PCA计算:
背景运动估计
作者这里额外用了一个网络预测背景的仿射变换: ,作者这里提出:从理论上来说,背景运动的训练可能会掺杂一部分前景。但是在实际训练过程中,发现前景的PCA分解比背景更加明显,所以很容易就被区分开了,在训练中没有遇到这种掺杂的情况。
分步生成动画
在FOMM中,对于input的图像和驱动视频其实是有一点约束的:源图像S和驱动视频的第一帧D1需要拥有大体相同的姿态,不然生成效果会受到影响。
本文中针对这一现象引入了一个额外的网络来对动画生成进行编码。
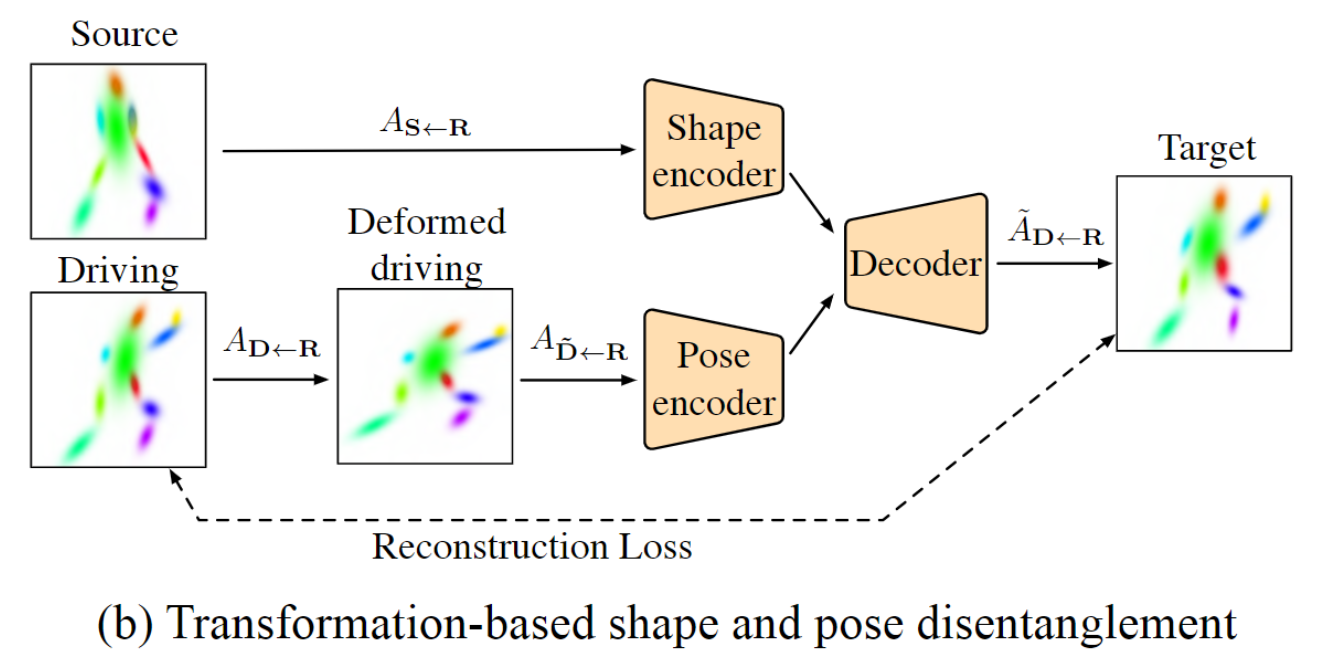
这里使用S来对前景的shape进行编码,然后用D来编码人物的pose,最后一起丢进一个网络生成最终的帧。由于和FOMM一样,在早期训练的过程中S和D其实是来自于同一段视频的,那显而易见S和D的shape是相同的,为了优化训练,作者在把这个D先进行了一些随机的形变。同时由于pose每一帧都不同,所以就不用额外处理了。